

導語:
隨著越來越多的企業認識到數據作為生產要素的價值,加快了企業數字化轉型,把完善企業級的數據治理體系作為企業數字化轉型的一個目標。長亮科技在大數據領域始終保持足夠的技術敏銳度,并積累了豐富的經驗與資產。為此,我們組織了一個系列專文,分期發表,與您一起探索更適合當下行業發展的數據觀,歡迎大家持續關注。
作者|長亮科技大數據研究院 內容|本篇共3960字,預計閱讀時間18分鐘
數據是組織的戰略資產,組織應該清楚地了解“數據的戰略價值”以及如何釋放和利用數據來產生積極的業務影響。定義數據戰略的起點首先是了解如何以一種經過深思熟慮、可重復、敏捷的方式使用數據來滿足企業內外各種需求,從集成主數據開始,部署可重用的高質量數據,最終實現企業級的集成語義層。
01 需求驅動與業務驅動 許多組織習慣性地將需求驅動軟件開發的傳統方法應用于數據平臺類系統建設中,數據服務部門按照業務部門的需求進行設計、開發提供數據服務。數據服務部門日常窮于應付業務部門用戶需求,還要面對需求部門的抱怨,同時承受用戶對數據的正確性、一致性以及時效性不滿意。由于需求的分析結果不能交互共享,難以在組織內獲得并充分利用數據的全部價值,不能消除企業層面的內部障礙。他們日復一日重復開發了數以萬計的表,知道自己一直在重復設計和分發相似的可能不正確或沖突的數據,服務于特定目的需求功能,而很少關注數據本身,持續創建孤島。 基于孤立的、局部的數據,只能產生業務特定的狹隘認知,缺乏支撐業務快速行動所需的黏合力、統一性與敏捷性,很難洞察出更多的業務價值,難以滿足業務發展與競爭需要。局部范圍的數據質量問題往往也難以及時發現,可能產生不良后果,如誤導客戶營銷,增加風險,導致合規成本飆升等等,投入巨資重復建設而獲得的價值很小。 設計良好的軟件解決方案可以利用封裝的可重用功能組件,獲得可靠的質量保證,同時避免了重復開發帶來的各種成本與不確定性。 數據價值不在于預定義的處理功能,而在于數據本身。以數據為中心是一種靈活的企業數據架構,在數據分析生態環境中部署可重用的高質量數據:采集最廣泛來源的數據,按照統一的規范清洗與轉換數據,清理冗余數據,提升數據的準確性、一致性與完整性等內在價值,形成反映企業完整的數據單一視圖。然后基于統一的數據創建不同視圖重用于多種目的,并確保需要它的每個人都可以訪問它,將分析轉移到數據中,而不是相反地——為每個需求復制數據。 在數據驅動的背景下,可以有效管理數據需求,新需求首先考慮如何從已搭建的集成數據環境中尋找是否有可重用的數據資產——獲得 “免費午餐”,不需要從頭開始,因而可以顯著降低開發和維護成本,減少尋找數據的時間,快速部署響應市場變化和各種需求。 數據能夠回答多少業務問題,取決于數據能產生多少有意義的組合。冗余數據與垃圾數據將使可能的組合發散,有價值的數據被淹沒在垃圾海洋中,不能產生更多的有價值的信息,使數據問題擴散,使用戶迷惑。數據集市的需求是確定的,因而數據是確定的,所能產生的組合也是確定的。 與分散的數據集市環境存在顯著不同,在企業集成數據環境中可以回答的跨領域的業務問題,隨著集成數據領域的增加,能回答的問題呈指數級增長,這是回答新問題、產生新價值的來源。 圖1:數據能夠回答多少業務問題,取決于數據能產生多少有效組合 比爾·恩門認為數據的集成是數據倉庫的第一真相。公司越大,這一點就越真實。數據集成是數據倉庫建設的核心內容,需要深入調研數據現狀,排除垃圾與冗余數據,定義與分類數據,建立數據之間關系。這些工作需要具備專業能力與持久韌性,一些供應商和顧問們忽視甚至排斥集成,但是在數據倉庫之外沒有其他方法可以進行集成,也沒有捷徑。 DAMA 等專業組織把數據集成與數據架構分別作為獨立的職能。如果把數據集成作為數據架構的一部分,表面上似乎降低了對數據管理相關領域的理解難度與復雜度,但也降低了數據集成的重要性,忽視了數據架構、數據集成、應用架構之間的關系。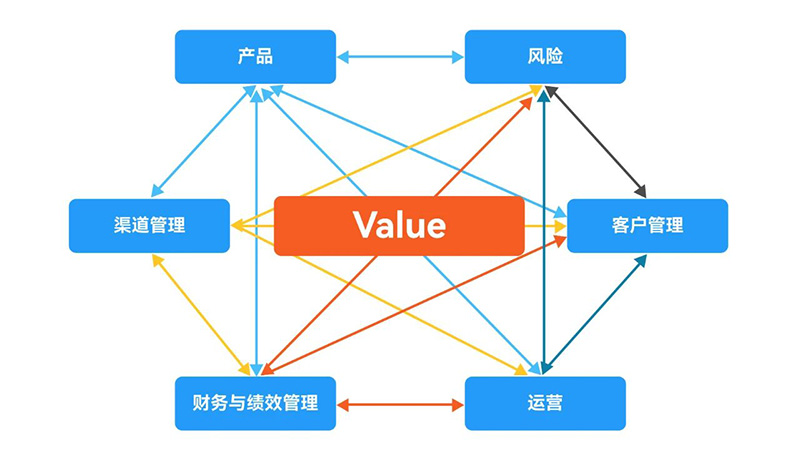
02
來自于高度的數據集成 彼得·德魯克說過,效率致力于正確地做事,效果則是做正確的事。 在數據倉庫20多年的發展過程中,不同供應商與用戶角色專業人員對數據集成的理解與認識存在很大差異,大多停留在表面的粗淺理解中,或故意忽略或回避“數據集成”的本質,既不能正確地做事,也不能做正確的事,數據集成的成熟度沒有得到質的提升。 代表高質量數據的完整性來自數據的高度集成。中文語境下的“整合”概念,并不能覆蓋英文語境“集成”概念的豐富內涵。英文語境中集成與完整性詞根相同,可以說數據集成的本質目標是實現數據的完整性,有清晰的標準要求。把多個數據源以通用格式存儲到數據湖中,然后轉換為目標物理模型結構的數據,存儲在相同的數據模型中,還不是完整的數據集成。 數據集成在邏輯數據建模過程中需要開展以下設計工作: 圖2:業務價值隨持續集成的數據增長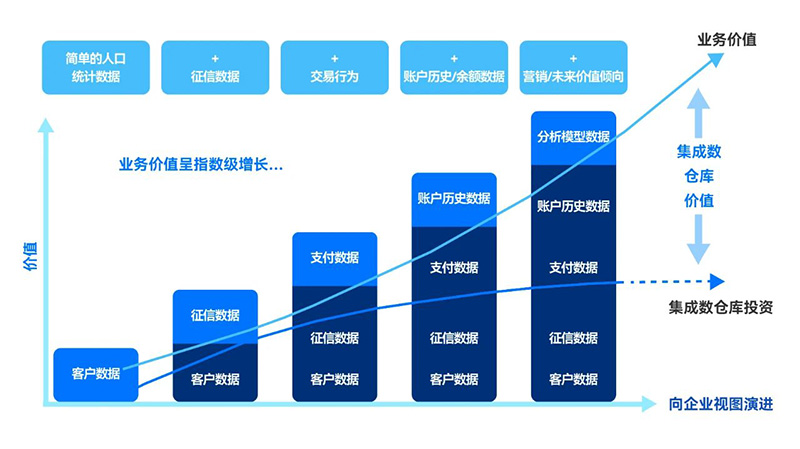
03
確定集成路線圖的初始數據范圍很重要,以確保承諾的價值交付時間表。數據部門人員通常會注意到:不同的應用需求,經常需要一些相同的數據,如客戶、機構、利率、匯率等主數據以及參考數據幾乎被所有應用所需。某些跨職能應用問題具有廣泛的業務影響,需要多個主題域來回答,提供前瞻性洞察。應采用務實的策略,盡快滿足業務的迫切需求,優先考慮公共需要的數據以及那些直接支持業務目標的已知業務問題并為后續新項目增加附加價值的數據,如風險合規和財務會計以及客戶、產品主數據等,杠桿撬動作用大,見效快。 以客戶數據為例,客戶數據是企業的戰略數據,企業價值的實現來自客戶。作為關鍵主數據的客戶數據,可能分布在組織內部不同業務系統中,來自不同數據源表達的信息要素各有側重,客戶的結構屬性可能有交叉、互補與差異,屬性的格式與值有差異,客戶記錄數也可能有差異,需要集成形成完整一致的集合。不同行業組織之間的客戶數據也存在以上這些差異。比如保險業、銀行業、電信業關注的信息要素可能有許多不同,包括客戶的定義信息、客戶購買產品歷史、行為偏好等,如何從客戶數據中獲取價值,都將成為獲得競爭優勢的關鍵途徑。 通過持續集成來自組織內外不同數據,可以形成客戶信息360° 視圖,了解產品與服務組合的變化對客戶的影響, 更快地識別客戶需求、問題、機會,擴大客戶群,給不同客戶提供不同服務,更有效地向客戶交叉銷售,提升客戶給企業帶來的價值。而在應用需求驅動的背景之下,如同盲人摸象,每個人得到的僅是局部片面的信息。 類似還有市場數據、產品數據的集成,特別是市場數據的集成,如基金市場的產品數據,銀行既可以代銷,也可以使用自有資金投資,本是同一產品概念,在通過不同的渠道接入不同的業務系統時設計了不一致的結構,維護了不同的數據集合,在進行整合時往往不被識別出來而設計成不同的概念,如代銷基金產品、共同基金產品。
04 結合最新技術與實踐 構建企業集成語義層 需要注意的是,盡管傳統的ETL或ELT數據集成流程已經存在了很多年,但數據的集成并不意味著一定伴隨數據的移動與復制,可以與數據的位置無關,基于云的數據集成平臺越來越普遍。復制需要時間與資源,復制過程可能導致數據泄漏、丟失或變形失真。在許多數據平臺與數據應用項目中,不斷復制數據,把數據從業務源系統復制到數據湖,再加工復制到數據倉庫,從數據倉庫遷移到各種集市,野蠻生長之后再進行治理。不同業務系統中的數據價值差異懸殊,一些非核心業務系統中有價值的數據很少,都復制到數據湖中是不明智的。ChatGPT 推動的生成式 AI 興起,點燃了對高質量數據的需求(質量、時效性與覆蓋范圍),傳統ETL或ELT方法不可能滿足這些要求。 結合應用數據架構、分類法、本體模型、業務詞匯表、元數據和知識圖譜的關鍵元素,表示組織知識和領域含義,聚合和統一非結構化和結構化數據,定義數據之間的關系,通過持續的數據探索,集成和編目,構建集成的業務語義層,提供來自任何領域的一致信息視圖,而無需將所有內容都復制移動到一個系統中。借助集成語義層,可以使用單一框架來訪問、理解和集成知識資產,這也是實現人工智能的基礎。 2016年 Noel Yuhanna(Forrester)首次提出了大數據編織概念,在Gartner推動下,數據編織已成為現代數據管理的重要趨勢。數據編織不強制數據物理遷移,通過主動元數據、知識圖譜、人工智能(AI)和機器學習(ML)等技術,動態整合跨平臺、跨環境的數據,實現數據的自動化探索、集成、治理和交付。數據編織已從“創新萌芽期”進入“期望膨脹期”,雖沒有全面成熟,數據虛擬化、主動元數據管理、AI驅動的數據集成等技術已相對成熟,可用于實現邏輯數據集成和動態編排。 結語:

